
by Matt Maliszewski
Updated: April 21, 2023

Article summary generated by ChatGPT:
Key findings:
ChatGPT, Open AI, Generative AI – these names are everywhere. There’s no denying that the „hype” for artificial intelligence is in full swing – specialized websites and popular information portals alike write about them endlessly.
I would like to critically assess whether this is another bubble that will soon burst, or a technological breakthrough we can’t ignore. I also want to ask the question of whether this is a technology that can be used in practice today, or if it is still too immature to successfully implement.
We’ve seen it many times: Metaverse, NFT, and Blockchain were all hot topics recently. It seems, however, that the inflated expectations for them have not materialized in the form of measurable business benefits, and the multi-billion investments pumped into them have mostly evaporated.
I have been dealing with chatbots (programs capable of conversing in a natural language) for over 10 years. The first solutions I implemented were devoid of artificial intelligence technology. They were based on fully deterministic algorithms – the creator of the chatbot fully controlled its behavior, and the bot itself was unable to say anything that had not been carefully edited beforehand.
This first generation of chatbots had a very limited ability to understand natural language, which translated into a poor user experience. In practice, the bot’s interlocutor had to be very understanding and use simple and concise phrases to be understood. Although such implementations were used in various business scenarios (many of which still work today), it was clear that the low glass ceiling would not allow for wide adoption of this technology.
The first small revolution came a few years ago. In “second generation” chatbots, we started using machine learning mechanisms based on artificial intelligence technology. As long as it is properly „trained”, a chatbot like this is able to understand its interlocutors much better than previous implementations. The aforementioned training consists of supplying the chatbot with a certain number of sample phrases (statements of users), on which the artificial intelligence model is built. A bot built in this way can make sense of a longer statement, often consisting of even a few sentences. For older implementations, this was an impenetrable brick wall.
From a human point of view, the volume of training data in this case is not small at all – it is usually comparable to a typical fiction book, such as „The Lord of the Rings” (the entire series of Tolkien’s novels is about 500,000 words). Despite this, in the world of AI we could describe the language models created on such a foundation as relatively small. Although it requires a lot of work and often surgical precision, we are able to manage this amount of data.
The introduction of the machine learning element means that we’ve given some “reasoning” ability to artificial intelligence. However, the creators of the chatbot still have tight control over both the training data affecting its behavior and the responses it gives to its interlocutors (this point is important from the perspective of further discussion of ChatGPT).
Most importantly, chatbots at this stage of development have already achieved high enough efficiency to be widely used in business. Depending on the industry and the scenarios implemented, the effectiveness of bots of this type ranges from 30 to 90%, with a median of around 60%. On one hand, this means that such a solution can automate the handling of more than half of the queries it receives. On the other hand, it is clear that we still have room for improvement.
That room for improvement is why the latest generation of chatbots based on large language models (LLM) – has been received with such enthusiasm. As the name suggests, they have been trained on a massive amount of data (an amount exceeding the capabilities of a human being) and an amount too large to exercise real control over.
This leads to the first important conclusion: when we use services offering ready-made LLM models, we have no knowledge about what data and sources were used to create them, and no way to influence it. But is it important? Chatbots based on engines of this generation – such as ChatGPT – offer not only great natural language understanding capabilities, but also incredible text creation capabilities. Let’s be honest – ChatGPT’s linguistic talents surpass the writing skills of most of us. Don’t believe it? I can easily prove it by asking it to write „swimming pool rules in the style of Lady Gaga songs” in less than 1 minute.
First impressions of ChatGPT will usually knock you off your feet. The model is brilliant, witty, creative, and at the same time believable. It is used by children and their parents, students and professors, lawyers and doctors, policemen and thieves, in short, almost everyone. Not surprisingly, the eyes of large and small companies have turned to it, considering whether and how its potential could be used to achieve various business goals. So is it a brilliant technology, ready for quick implementation? No – well, not yet anyway.
The first and most important problem is the so-called „hallucinations”. Basically, an LLM-based chatbot can write complete nonsense in a very credible way. Fake the truth, confabulate, and mix up the facts. For serious business, this is of great importance. A chatbot that hallucinates can mislead customers, give contradictory instructions to employees, and change their mind about the same information every 3 seconds.

The bot’s answer is specific, linguistically correct, and tailored to the user’s needs. The only problem is that none of the books mentioned above exist! We call these cases “recommendations without expertise” – a vivid example of LLM hallucinations.
Another problem I’ve already mentioned is the lack of full control over the operation of the bot. This means that there is no way to explain some of its behavior, which in some cases can be particularly frustrating. How do we improve something if we can’t explain how it works? How can we enforce compliance with the law and company policy from such a rebellious „employee”?
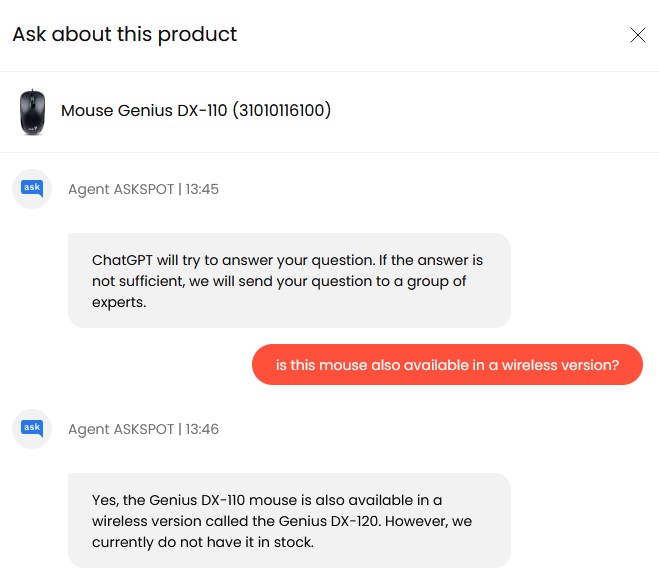
In this example, the Polish online store Morele.net’s chatbot gave a false answer that could easily mislead the customer. The Genius DX-120 mouse recommended by chatbot is not wireless. Kudos to this store, however, for introducing such a bold innovation!
The third and perhaps most painful problem is the non-compliance of services offering LLM models with the European Union’s General Data Protection Regulation (EU GDPR). An out-of-the-box solution is simply not able to guarantee that the entire range of privacy protection and personal data processing requirements imposed by European law are met.
From a broader perspective, the entire legal environment regarding generative models of artificial intelligence is chaotic. There are still no relevant legal regulations, and the behavior of the authorities of various countries is unpredictable and can be even radical, such as the ban on the processing of personal data imposed on OpenAI by the Italian government.
At this stage, enthusiasm usually cools down and „hooray-optimism” fades away. It turns out that there are two sides to every story – one is associated with new opportunities, the other with real risk. But then again, isn’t this true of any major business opportunity?
Moving from theory to practice: in our work, we have been watching the development of large language models for a long time. Interestingly, we went the opposite direction of most people. We started out as skeptics, but over time enthusiasm prevailed.
We focused our development work on making sure we had the most control possible over the „third generation” chatbot. Here are a few of the challenges we’ve already solved:
These are not just experiments. Soon we will make available for free testing our PerfectBot GPT product. It will be dedicated to eCommerce and will use these solutions, in particular the mechanisms of protection against hallucinations.

In the example above, we sent the same query to the bot that triggered the hallucinations shown in the previous image. This time, the „fantasy” of the bot is radically limited.
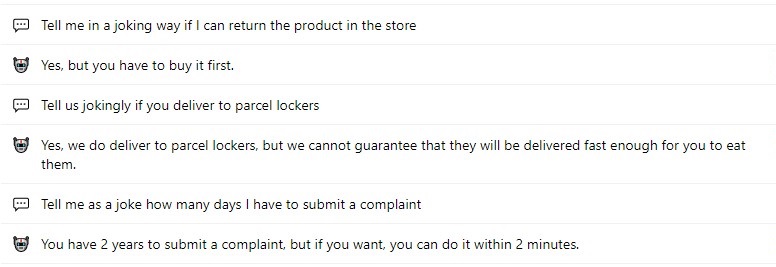
These examples show why it is still worth looking for methods of combining business knowledge provided to the chatbot with the „creative” possibilities of large language models. All these answers provide accurate information about our client’s business. Not all pranks are successful, but that’s true of people as well, right?

In the example above, the chatbot handled a very complex query correctly by combining information taken from different areas of its knowledge base. A separate answer was required for each of the three situations listed in the question.
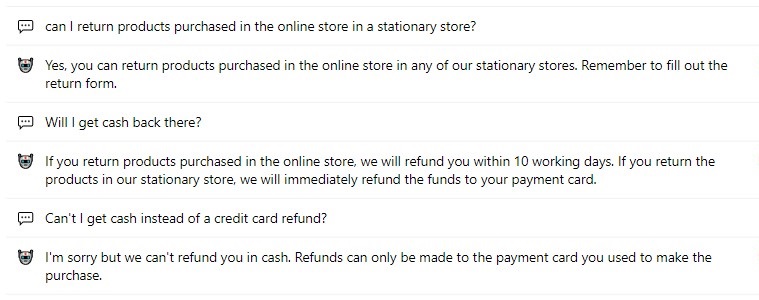
The above example shows a longer exchange between the user and the bot, where the chatbot properly maintains the context of the conversation and allows the user to gradually deepen the questions.
In the light of the challenges posed by the use of LLM models, it is clear that not every business will decide to take a step in this direction soon. I expect that the bravest eCommerce companies will very soon decide to use generative AI (the first pilot implementations have already appeared), this step will be much more difficult for the medical, financial, and insurance industries.
For companies that take a more cautious approach, there is one more, still very attractive way: it is possible to build a hybrid chatbot using a large language model with an older generation solution. Then you can obtain a higher quality (effectiveness) of the chatbot’s operation, derived from the capabilities of a large language model while still maintaining high control over its behavior. The bot will not say anything that has not been carefully edited and accepted by the business.
The point is not to evaluate the current situation as a zero-one. New technology has brought new possibilities, but it also has disadvantages and limitations. We can use this innovation to varying degrees, depending on the industry and the business scenarios being implemented.
So we have a simple and universal recommendation, as for any new technology:
We at PerfectBot will be happy to help with this!

The relatively low cost of AI implementation means that the technology has spread to every major industry on the planet. We’ve put together a list of 10 areas where AI has the ability to be a game-changer in eCommerce.
Read more
According to Business Insider, the chatbot market will nearly quadruple by 2024, growing from $2.6 billion to $9.4 billion at a CAGR of 29.7%. Read on to see 7 top trends that we at PerfectBot believe will shape the chatbot universe this year.
Read moreBuilt for Gorgias
Enriched for Maximum Accuracy
Instant Setup
The smartest AI Agent for Gorgias





