by Lucas Lewandowski
Updated: December 12, 2022

In this article, we will describe the mistakes that are made when assessing the effectiveness of chatbots and the evaluation method we have developed at PerfectBot based on the experience of automating 6 million conversations for the largest companies in the eCommerce industry.
Where does the problem of incorrectly measuring the performance of chatbots come from?
The described chatbot’s metrics relate to Conversational AI Chatbots, i.e. chatbots that try to answer questions asked in natural language.
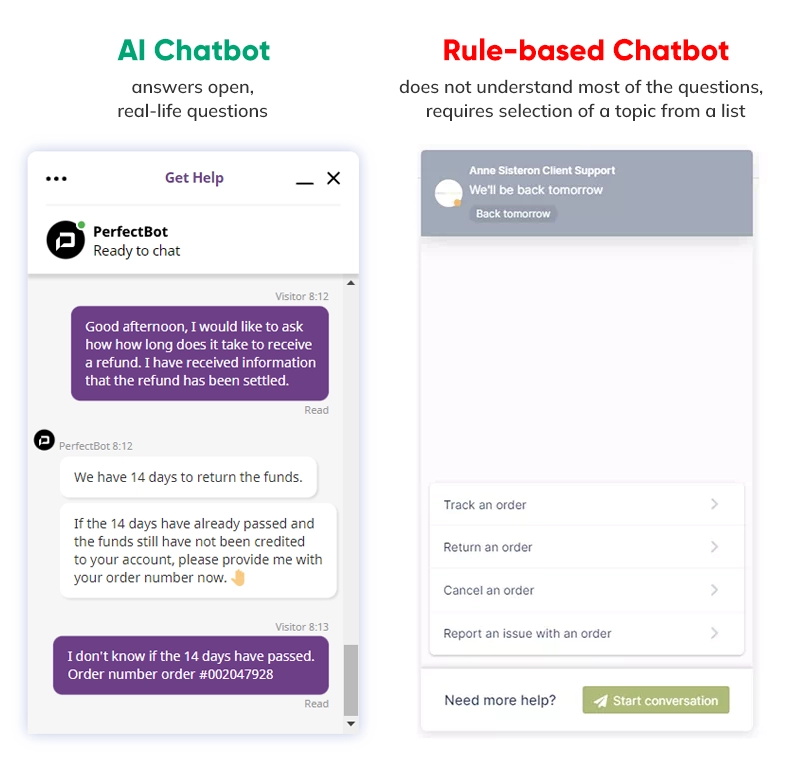
In the case of the Rule-Based Chatbots, we do not evaluate the effectiveness of answering questions, but how well the chatbots simply go through the process. The evaluation is therefore not a challenge. Since Rule-Based Chatbots do not answer open questions, but instead work like a closed-choice form, their effectiveness should be 100% (just like any other form on the website).
Rule-based bots only support specific processes (e.g. checking the status of a complaint) and therefore their impact on relieving customer service is limited.
Customers want to ask questions in their own way, using natural language, and therefore they strive to contact the Customer Service Center. That’s why only a conversational chatbot that tries to understand natural language can handle a wide range of requests. We will focus on the evaluation of these bots.
Mistake # 1 – Do not consider every conversation ended by the chatbot as a properly automated conversation.
The first mistake made even by global chatbot providers is the assumption that if the bot did not switch the chat to a consultant, it was automated, correctly handled, by default.
At best, such a chat was „contained,” and therefore should not count towards the „automation rate”, but rather the „containment rate” known from the evaluation of the helpline’s IVR systems. The containment rate says little about the effectiveness of the chatbot.
In the case of a text-based conversational bot, the lack of escalation to a human agent does not mean proper service. This is shown in the example interview below.
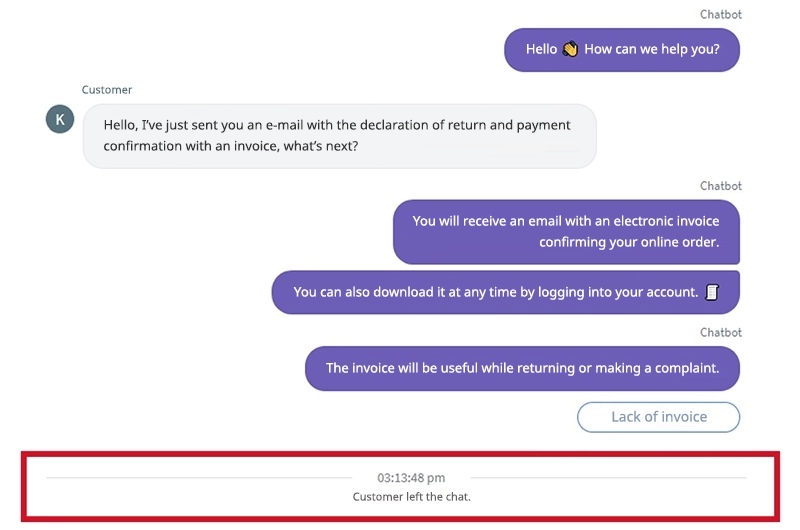
The client received the wrong answer and left the conversation without saying a word. This is a common problem. We are dealing here with the so-called „false positive” answer, i.e. the chatbot misunderstood the question and gave the wrong answer. Only a human who has read the conversation can accurately judge it reliably because, according to the bot, the conversation was conducted correctly – since it gave an answer and there was no further escalation.
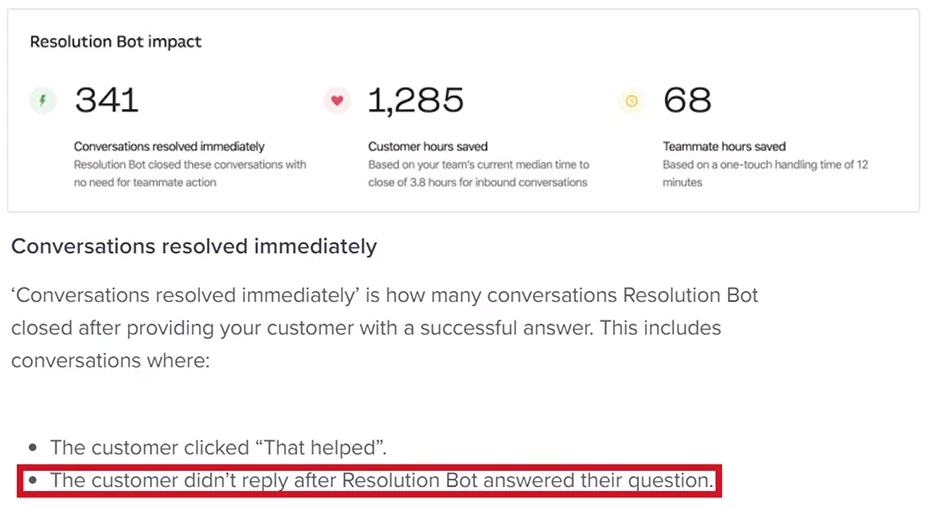
Mistake # 2 – No response from the user after the chatbot responds does not equate to a properly automated conversation.
Even leading chatbot companies use this far-fetched assumption to evaluate the performance of chatbots. Below you can see how Intercom – one of the leading players implementing chat and customer service automation tools – considers all conversations properly automated if the client does not answer after receiving the bot’s response.
Mistake # 3 – The fact that the user „clicked” on the bot’s menu does not mean that they got a response.
The last error of evaluation is made with bots that promote the selection of answers from the menu, rather than giving specific answers to open-ended questions.
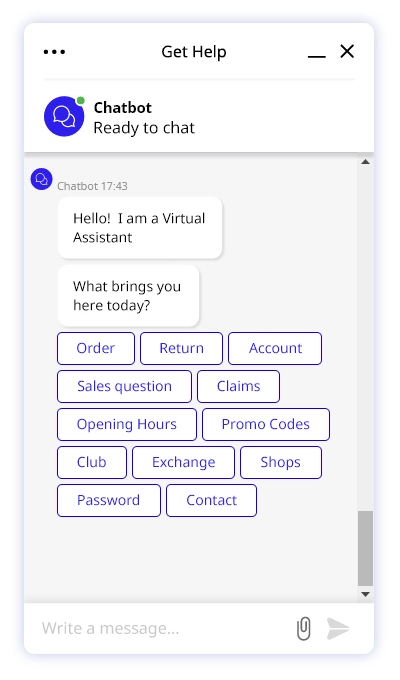
If a user does not ask a question in their own words, and instead just clicks on something in the start menu, we never really know what problem they initially had – and thus we can’t be sure whether or not we helped them.
Such 'click-through’ conversations include automated ones, but not all of them should be considered as such. A person who has not found their answer in the bot’s menu, a moment later can call the hotline or send an email.
The automation rate is the basis for estimating the business effects of the chatbot’s implementation, e.g. savings. If it is based on incorrect assumptions, it distorts all calculations of business benefits.
Therefore, when analyzing a business-case, we should always ask the question: How exactly was the automation rate calculated?
So far, our chatbots have handled 6 million conversations for the largest Retail & eCommerce companies. We read and manually assessed tens of thousands of these conversations. This allowed us to develop the following method to evaluate the bots’ effectiveness.
# 1 – Chatbot evaluation should be partially manual.
Relying only on chatbot metrics obtained automatically (e.g. percentage of escalation or recognized questions) is insufficient. A conclusive assessment requires the participation of a human reading and evaluating a statistically significant sample of conversations. Therefore, during the optimization period of each newly implemented PerfectBot, we read and evaluate up to 30 percent of conversations.
# 2 – Chatbot evaluation should be transparent.
The assessment should be easy to check. That is why at PerfectBot every conversation assessed by an expert is tagged in the chats archive. The client not only gets an aggregated performance score, but can verify every single rating. It builds confidence in the results.
# 3 – The chatbot assessment should be related to the final result of the conversation.
The final effect of the conversation should be assessed, not whether the bot gave a single answer in the conversation.
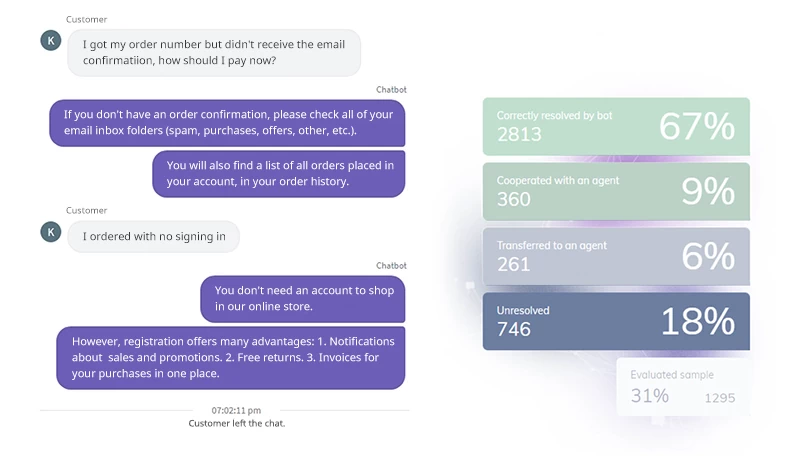
At PerfectBot, we classify conversations into 4 main groups.
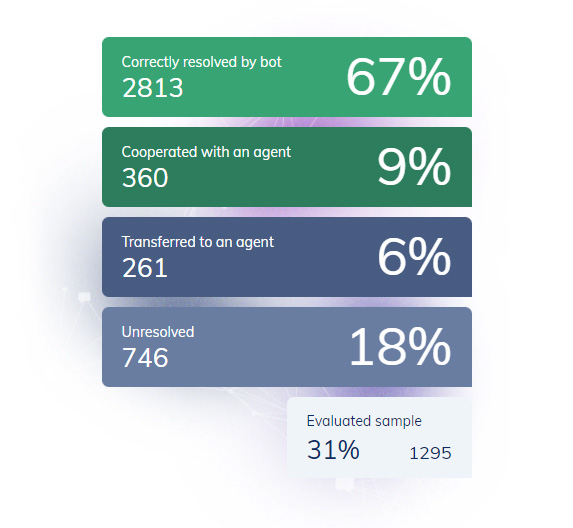
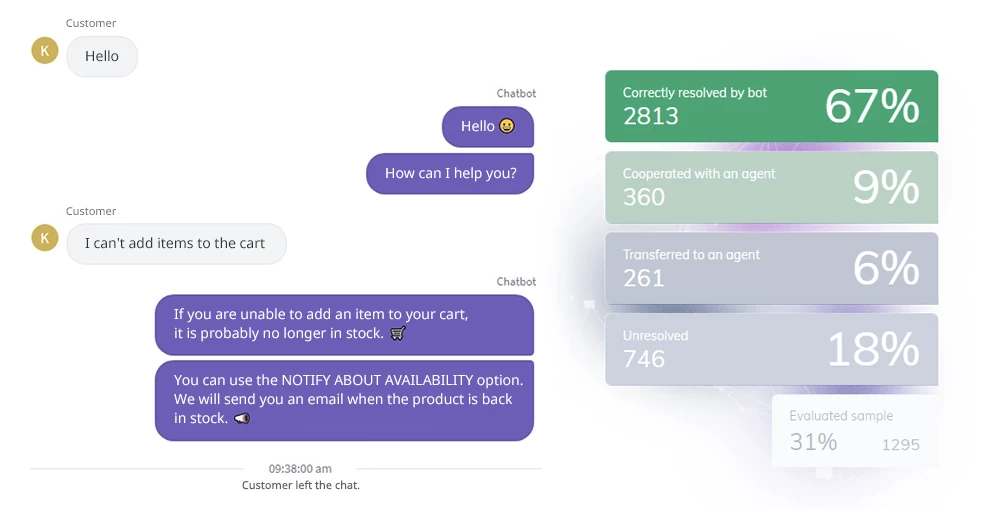
Correctly resolved by bot – perfect answer
The chatbot perfectly understood what the user needed, despite the fact that the problem was described in a nuanced way.


Correctly resolved by bot – good answer
It can be assumed that the bot solved the case correctly, although due to the lack of feedback, it cannot be certain.
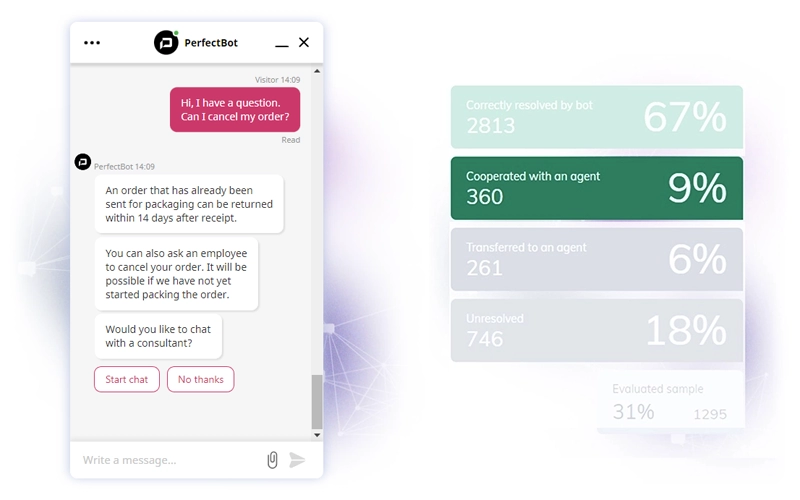
Cooperated with an agent
The chatbot correctly recognized the question, gave a partial answer, which may have been sufficient. At the same time, it offered the user the possibility of contacting a support agent.
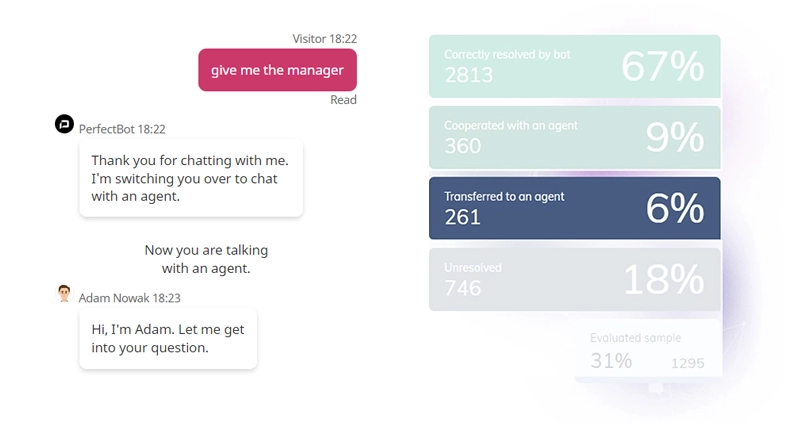
Transferred to an agent
The user asked to switch to a support agent after the bot gave a wrong answer.
Unresolved – insufficient answer
The bot did not specifically answer the user’s first question and was therefore not understood. It repeated the reply and the user quit, possibly dissatisfied with the insufficient response.

Unresolved – incorrect answer
In order to reliably measure the effectiveness of a chatbot, you should:
The truth may be difficult for many chatbots, but it will force them to grow. We encourage you to conduct a thorough assessment of the effectiveness of chatbots, because that is the first step to make bots become a significant relief for customer service, instead of a frustration.

Can any chatbot ever really replicate the live chat experience? If not, could a thoughtful combination of the two provide the best aspects of both? In this article, we’ll present both solutions in more detail.
Read more
Before choosing specific tactics and tools to improve customer support in an e-commerce business, it is vital to form an overarching strategy and approach to create a foundation for future success.
Read moreChatbot tailored for
customer service in eCommerce
The highest
resolution rate
Ready
in 2 weeks
The smartest AI Agent for Gorgias





